- Info@SaminRay.Com
- 88866172 021
مقدمه ای بر رمزگذارهای خودکار(introductions to Autoencoders)
بطور کلی در خصوص مدلهای Auto Encoder چنین می توان گفت که برای بازسازی داده های ابعاد بالا با استفاده از یک مدل شبکه عصبی و یک لایه bottleneck در وسط اختراع شده است.
انواع مدلهای Autoencoder
بطور کلی در خصوص مدلهای Auto Encoder چنین میتوان گفت که برای بازسازی دادههای ابعاد بالا با استفاده از یک مدل شبکه عصبی و یک لایه bottleneck در وسط اختراع شده است. لایه bottleneck لایه است که نسبت به لایههای قبلی از نودهای کمتری تشکیل شده است. یکی از کاربردهای جانبی چنین ساختاری کاهش بعد داده میتواند باشد، به این ترتیب که لایه bottleneck یک embedding با ابعاد پایین از داده ورودی ایجاد میکند که از آن میتوان برای بازنمایش داده با ابعاد کمتر یا فشرده سازی دادهها استفاده کرد. در ادامه به معرفی انواع رایج این مدلها خواهیم پرداخت.
مدل Autoencoder ابتدایی
Autoencoder یک شبکه عصبی بمنظور یادگیری یک تابع همانی به روش unsupervised برای بازسازی ورودی بهمراه فشرده سازی دادهها به منظور کشف نمایش بهتر و فشرده است. این ایده در دهه 1980 شکل گرفت و سپس در مقاله ای با عنوان Reducing the Dimensionality of Data with Neural Networks در سال 2006 توسط Hinton & Salakhutdinov به چاپ رسید.
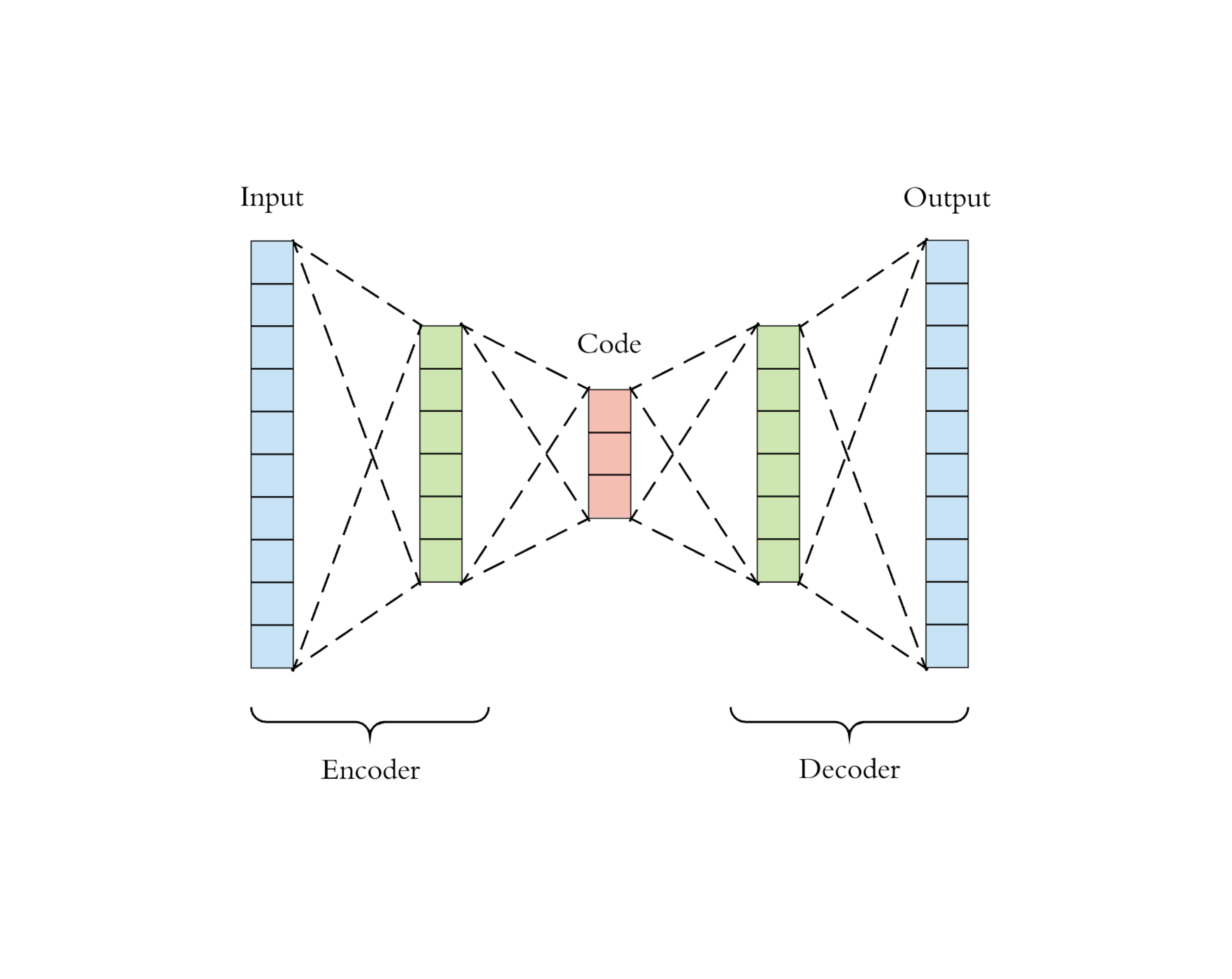
مدل Auto Encoder از دو شبکه تشکیل شده است:
- شبکه Encoder: این شبکه ورودی ابعاد بالا را به کدهایی با ابعاد کم در لایه latent تبدیل میکند. اندازه ورودی این شبکه بزرگتر از اندازه خروجی آن است.
- شبکه Decoder: شبکه Decoder دادههای ورودی را از کدهای تولید شده در لایه latent بازتولید میکند.

تصویر معماری مدل Auto Encoder
شبکه Encoder در واقع کاهش بعد انجام میدهد. علاوه بر این، ساختار مدل Autoencoder به گونه ای طراحی شده است تا بتواند بازسازی داده از کد را به روشی بهینه انجام دهد.
این مدل شامل یک تابع encoder بصورت (.)gᵩ و یک تابع decoder بصورت (.)fᵩ است. به این ترتیب کدهای باز نمایش داده ورودی در لایه latent بصورت (Z=gᵩ(X و ورودی های بازسازی شده بصورت (X′= fⲑ(gᵩ(X نمایش داده میشوند. پارامترهای φ و θ بگونه ای توامان با هم اموزش داده میشوند تا شبکه بتواند بازسازی دقیتری از داده ورودی در خروجی ایجاد نماید. به گونه ای که ((X≈ fθ(gφ(X باشد یا بعبارتی دیگر پارامترهای φ و θ باید بگونه ای آموزش ببینند تا شبکه تابع همانی را به درستی یادبگیرد. بمنظور سنجش کیفیت فرایند آموزش یک Autoencoder میتوان میزان تفاوت مابین بردار ورودی و بردار بازسازی شده را با استفاده از معیارهای cross entropy یا MSE در نظر گرفت.
Denoising Autoencoder
باتوجه به اینکه مدل Autoencoder ابتدایی یک تابع همانی را میآموزد به این ترتیب در مواقعیکه پارامترهای شبکه بیشتر از تعداد نمونهها باشد آنگاه احتمال overfit شدن به شدت افزایش خواهد یافت. برای جلوگیری از overfit شدن شبکه و همچنین بهبود robustness آن مدل Denoising Autoencoder در سال 2008 توسط Vincent و همکارانش به عنوان یک روش اصلاحی برای مدل Autoencoder ابتدایی پیشنهاد گردید. در این روش ورودی با اضافه کردن نویز یا پوشاندن برخی از مقادیر به صورت تصادفی تا حدی مخدوش میشوند و مدل با هدف بازیابی داده اصلی (ورودی بدون نویز) آموزش داده میشود.
 تصویری معماری مدل Denoising Auto Encoder
تصویری معماری مدل Denoising Auto Encoder
ایده اصلی شکل گیری چنین مدلی نحوه عملکرد ذهن انسان در مواجهه با تصاویر مخدوش شده است. همانطور که ذهن انسان با دیدن تنها یک بخشی از یک تصویر سعی در حدس زدن مابقی جزییات آن تصویر دارد مدل Denoising Autoencoder نیز با استفاده از اطلاعات موجود در داده ورودی و نحوه ارتباط ابعاد با یکدیگر سعی در حذف نویز و پیش بینی داده اصلی دارد.
در مورد دادههای ابعاد بالایی که ابعاد آن دارای redundancy نیز هستند، مانند تصویر، مدل تلاش میکند تا با جمع آوری اطلاعات از همه ابعاد و ترکیب آنها نسبت به بازسازی داده اصلی اقدام کند و به این ترتیب از توجه بیش از حد مدل به یک بعد یا ویژگی کاسته خواهد شد و احتمال overfit شدن شبکه کاهش مییابد و علاوه بر آن در چنین حالتی لایه latent مقاومتری ساخته خواهد شد. نویز مورد نظر از طریق یک تابع تصادفی ایجاد میشود. در بخش Expriment مقاله Denoising Auto Encoder به نحوه ایجاد نویز اشاره شده است. در آنجا آمده است که برای ایجاد نویز یک بخش مشخصی از داده ورودی بصورت تصادفی برابر صفر میشوند، بسیار مشابه لایه dropout که بعدها در سال 2012 توسط Hinton و همکارانش معرفی گردید.
Sparse Autoencoder
مدل Sparse Autoencoder به منظور کاهش احتمال overfit شدن و افزایش robustness یک شرط Sparse در activation functionهای لایه پنهان اعمال میکند. این شرط مدل را مجبور میکند که فقط تعداد کمی از واحدهای پنهان را همزمان فعال کند، یا به عبارت دیگر وجود این شرط سبب میشود یک نورون پنهان بیشتر اوقات غیرفعال باشد. با توجه به اینکه توابع فعال سازی رایج عبارتند از sigmoid، tanh، relu، leaky relu یک نورون زمانی فعال میشود که ورودی نزدیک به 1 باشد و با مقدار نزدیک به 0 غیرفعال میشود.
با فرض اینکه sl نرون در لایه lام وجود داشته باشد آنگاه تابع فعالسازی برای نرون jام در این لایه به صورت aj(l)(.), j=1, ..., sl نمایش داده خواهد شد. میزان فعال شدن این نرون که بصورت ῤj نمایش داده میشود انتظار میرود یک عدد کوچک به اندازه ⍴ باشد و از آن معمولا بعنوان پارامتر پراکندگی نیز یاد میشود، بطور معمول این پارامتر به صورت ⍴=0.05 تنظیم میشود. شرط فوق از طریق اضافه کردن یک جمله penalty به تابع هزینه بدست میآید. تابع هزینه مدل sparse autoencoder بصورت زیر است.
LSAE(θ) =L(θ) +ꞵΣLl=1Σslj=1DKL(⍴||ῤ(l)j)
معیار واگرایی KL میزان اختلاف بین دو توزیع برنولی را میسنجد و پارامتر ꞵ میزان penalty مورد نظر را تعیین میکند.
Variational Autoencoder
ایده مدل Variational Autoencoder که به اختصار به آن VAE گفته میشود در سال 2014 توسط Kingma و Welling ارایه شد و اساسا شباهت بسیار کمی به مدلهای autoencoder مطرح شده تا کنون دارد و عمیقا به مدلهای variational bayesian و مدلهای گرافیکی شبیه است. در VAE بجای نگاشت دادن ورودی به بردارهای ثابت، هدف نگاشت دادن ورودی به یک توزیع است. در صورتیکه این توزیع را با pΘ نمایش بدهیم آنگاه رابطه بین داده ورودی x و بردار کدگذاری z لایه latent با استفاده آیتمهای زیر کاملا قابل تعریف خواهد بود.
- Prior pΘ(𝘇)
- Likelihood pΘ(𝘅|𝘇)
- Posterior pΘ(𝘇|𝘅)
با فرض اینکه پارامترهای بهینه برای توزیع مورد نظر با *Θ نشان داده شود آنگاه به منظور تولید نمونه مشابه با نمونه داده ورودی گامهای زیر باید طی شوند.
- ایجاد یک نمونه (i)𝘇 از توزیع (𝘇)*pΘ
- ایجاد نمونه (i)𝘅 با استفاده از توزیع شرطی((pΘ*(𝘅|𝘇=𝘇(i
پارامتر بهینه *Θ پارمتری است که احتمال تولید نمونههای داده واقعی را به حداکثر میرساند و از طریق رابطه زیر قابل محاسبه است.
Θ* = argmaxΘⲠni=1pΘ(𝘅(i))
متاسفانه محاسبه ((pΘ(𝘅(i کار ساده ای نیست زیرا ارزیابی تمام مقادیر ممکن برای  بسیار زمانبر است. برای محدود کردن فضای عددی و افزایش سرعت جستجو از یک تخمینگر برای تولید خروجی که بسیار شبیه به کد تولیدی به شرط دریافت ورودی
بسیار زمانبر است. برای محدود کردن فضای عددی و افزایش سرعت جستجو از یک تخمینگر برای تولید خروجی که بسیار شبیه به کد تولیدی به شرط دریافت ورودی  باشد استفاده میشود. تابع تخمین گر را بصورت(𝘇|𝘅)qᶲ نمایش داده میشود.
باشد استفاده میشود. تابع تخمین گر را بصورت(𝘇|𝘅)qᶲ نمایش داده میشود.
حال با این شرایط ساختار یک شبکه VAE مشابه یک شبکه autoencoder خواهد شد بگونه ای که تابع احتمال شرطی (𝘅|𝘇)pΘ بعنوان مدل ژنراتوری را میتوان مشابه با بخش decoder یا(𝘅|𝘇)fΘ در نظر گرفت که به آن decoder احتمالاتی نیز گفته میشود. تابع تخمین (𝘅|𝘇)fΘ یک encoder احتمالاتی است و مشابه با(𝘅|𝘇)fΘ عمل میکند.
 مدل گرافیکی نمایش یک شبکه VAE. خطوط پیوسته نشان دهنده توزیع ژنراتور(.)pΘ و خطوط منقطع نشان دهنده توزیع (𝘇|𝘅)qᶲ که از آن برای تخمین (𝘇|𝘅)pΘ استفاده میشوداست.
مدل گرافیکی نمایش یک شبکه VAE. خطوط پیوسته نشان دهنده توزیع ژنراتور(.)pΘ و خطوط منقطع نشان دهنده توزیع (𝘇|𝘅)qᶲ که از آن برای تخمین (𝘇|𝘅)pΘ استفاده میشوداست.

تصویر معماری مدل VAE
مراجع
https://lilianweng.github.io/posts/2018-08-12-vae/
https://lilianweng.github.io/posts/2018-08-12-vae/
https://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.459.3788&rep=rep1&type=pdf