- Info@SaminRay.Com
- 88866172 021
مدلهای Diffusion چگونه کار می کنند؟
الگوریتم های یادگیری ماشین و هوش مصنوعی برای حل مسائل پیچیده و افزایش درک ما از داده ها به طور مداوم در حال تکامل هستند
الگوریتمهای یادگیری ماشین و هوش مصنوعی برای حل مسائل پیچیده و افزایش درک ما از دادهها به طور مداوم در حال تکامل هستند. یکی از گروههای جالب مدلهای هوش مصنوعی، مدلهای Diffusion هستند که به دلیل توانایی خود در گرفتن و شبیهسازی فرآیندهای پیچیده مانند تولید داده و سنتز تصویر، توجه قابل توجهی را به خود جلب کردهاند.
Diffusion چیست؟
Diffusion یک پدیده طبیعی اساسی است که در سیستمهای مختلف از جمله فیزیک، شیمی و زیست شناسی مشاهده میشود. بعنوان مثال اسپری کردن عطر را در نظر بگیرید. در ابتدا، مولکولهای عطر به شدت در نزدیکی محل اسپری متمرکز میشوند. با گذشت زمان، مولکولها پراکنده میشوند. Diffusion فرآیند حرکت ذرات، اطلاعات یا انرژی از ناحیه ای با غلظت بالا به ناحیه ای با غلظت کمتر است. این پدیده به این دلیل اتفاق میافتد که سیستمها تمایل دارند به تعادل برسند، جایی که غلظتها در سراسر سیستم یکنواخت میشوند.
در زمینه یادگیری ماشین و تولید داده، Diffusion به یک رویکرد خاص برای تولید داده با استفاده از یک فرآیند تصادفی شبیه به زنجیره مارکوف اشاره دارد. مدلهای Diffusion با استفاده از دادههای ساده که به راحتی تولید میشوند بعنوان ورودی استفاده میکند و با تبدیل تدریجی آن به نمونه پیچیدهتر و واقعیتر نمونه جدید را ایجاد میکند.
مدل Diffusion در یادگیری ماشین چیست؟
مدلهای Diffusion، مدلهای Generative هستند، به این معنی که بر اساس دادههایی که روی آنها آموزش دیدهاند، دادههای جدیدی تولید میکنند. برای مثال، یک مدل Diffusion آموزشدیده بر روی مجموعهای از چهرههای انسان میتواند چهرههای انسانی جدید و واقعی با ویژگیهای مختلف ایجاد کند، حتی اگر آن چهرههای خاص در مجموعه داده آموزشی اصلی وجود نداشته باشند.
این نوع مدلها بر یادگیری گام به گام نحوه تکامل یک توزیع و تبدیل شدن آن به یک توزیع داده پیچیده با شروع از یک نمونه داده تمرکز دارند. به طور کلی مدلهای Diffusion وظیفه تبدیل یک توزیع ساده که به راحتی قابل نمونهبرداری نیز باشد مانند یک توزیع گاوسی، به یک توزیع پیچیدهتر مورد انتظار است. این تبدیل از طریق یک سری عملیات معکوس به دست میآید. هنگامی که مدل فرآیند تبدیل را یاد گرفت، میتواند نمونههای جدیدی را با شروع از نقطهای در توزیع ساده تولید کند و به تدریج آن را به توزیع دادههای پیچیده دلخواه Diffuse کند.
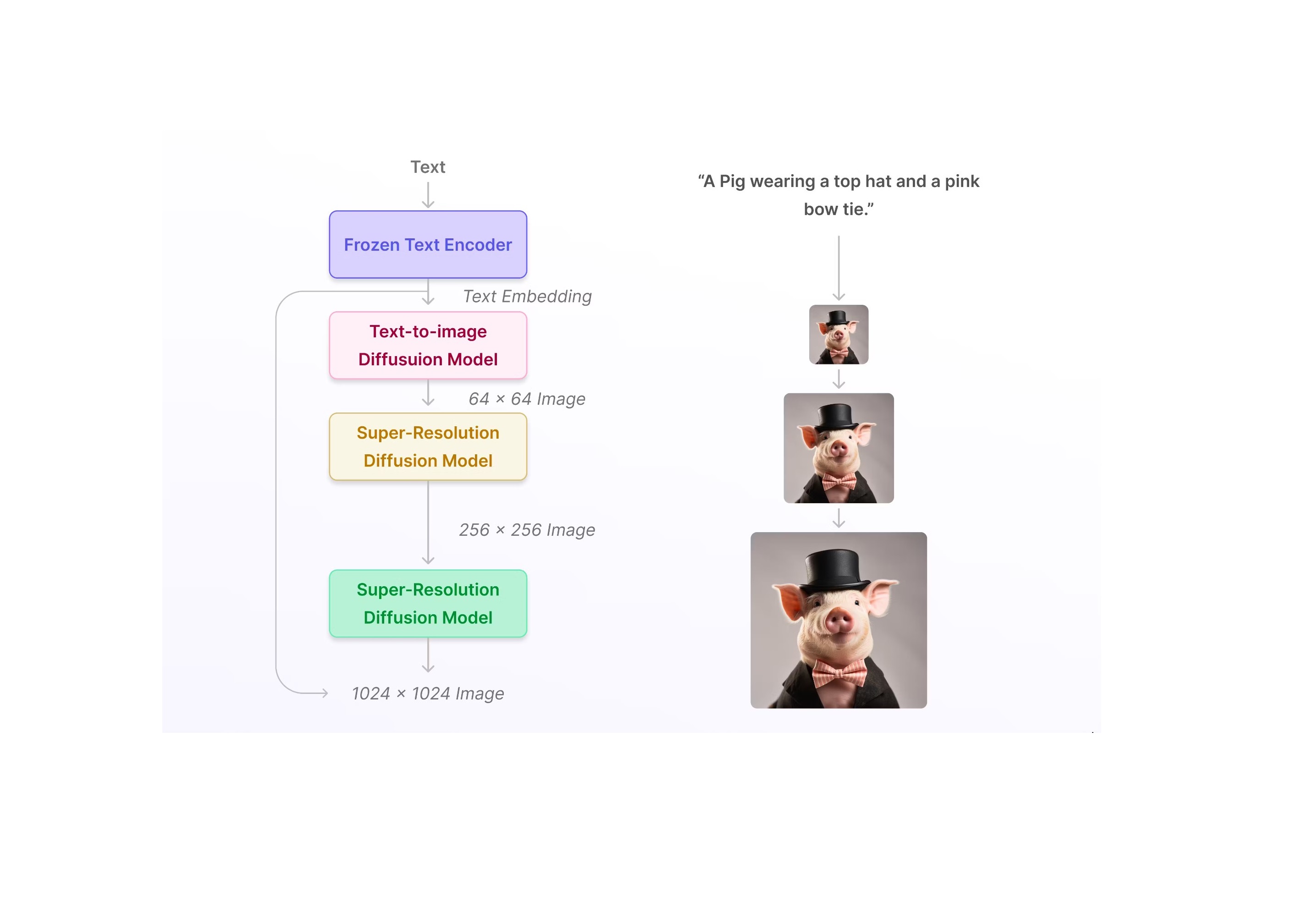
مدل Diffusion چگونه کار میکند؟
مدلهای Diffusion دستهای از مدلهای Generative هستند که بر اساس مفهوم «Reverse Diffusion» برای شبیهسازی تولید داده عمل میکنند. بیایید نحوه عملکرد مدلهای انتشار را به صورت گام به گام بررسی کنیم:
پیش پردازش داده ها
مرحله اولیه شامل پیش پردازش دادهها برای اطمینان از Scaling و Centring مناسب داده است. به طور معمول، استانداردسازی برای تبدیل دادهها به توزیعی با میانگین صفر و واریانس یک اعمال میشود. این دادهها را برای تبدیلهای بعدی در طول فرآیند Diffusion آماده میکند و مدلهای Diffusion را قادر میسازد تا به طور مؤثر تصاویر پر نویز را مدیریت کنند و نمونههای با کیفیت بالا تولید کنند.
انتشار به جلو
در طول فرایند انتشار رو به جلو، مدل با نمونهای از یک توزیع ساده، معمولاً یک توزیع گاوسی، شروع میکند و دنبالهای از تبدیلهای معکوس را برای انتشار گام به گام نمونه اعمال میکند تا زمانی که به توزیع داده پیچیده مورد نظر برسد. هر مرحله انتشار پیچیدگی بیشتری را به دادهها وارد میکند و الگوهای پیچیده و جزئیات توزیع اصلی را به تصویر میکشد. این فرآیند را میتوان به عنوان افزودن تدریجی نویز گاوسی به نمونه اولیه که منجر به تولید نمونههای متنوع و واقعی با گسترش فرآیند انتشار میشود در نظر گرفت.
آموزش مدل
آموزش یک مدل Diffusion شامل یادگیری پارامترهای تبدیلهای معکوس و سایر اجزای مدل است. این فرآیند معمولاً شامل بهینهسازی یک تابع هزینه است، که ارزیابی میکند که چگونه مدل میتواند نمونهها را از یک توزیع ساده به نمونههایی تبدیل کند که بسیار شبیه توزیع دادههای پیچیده هستند.
انتشار معکوس
هنگامی که فرآیند انتشار رو به جلو نمونه ای را از توزیع دادههای پیچیده تولید میکند، فرآیند انتشار معکوس آن را از طریق دنباله ای از تبدیلهای معکوس به توزیع ساده نگاشت میکند. از طریق این فرآیند انتشار معکوس، مدلهای انتشار میتوانند نمونههای داده جدیدی را با شروع از یک نقطه در توزیع ساده و انتشار گام به گام آن به توزیع دادههای پیچیده دلخواه تبدیل کنند. نمونههای تولید شده شباهت قابل توجهی به توزیع دادههای اصلی دارند و مدلهای انتشار را به ابزاری قدرتمند برای کارهایی مانند سنتز تصویر، تکمیل دادهها و حذف نویز تبدیل میکنند.
مزایای استفاده از مدلهای انتشار
مدلهای انتشار مزایای متعددی نسبت به مدلهای Generative سنتی مانند GAN و VAE دارند. این مزایا ناشی از رویکرد منحصر به فرد آنها برای تولید داده و استفاده از انتشار معکوس است.
کیفیت و هماهنگی تصویر
مدلهای Diffusion در ایجاد تصاویر با کیفیت بالا با جزئیات دقیق و بافتهای واقعی مهارت دارند. با گرفتن پیچیدگی اساسی توزیع دادهها از طریق انتشار معکوس، مدلهای Diffusion تصاویری با ساختارهای منسجمتر و مصنوعات کمتری در مقایسه با مدلهای مولد سنتی تولید میکنند. مقاله OpenAI با عنوان Diffusion Models Beat GANs on Image Synthesis نشان میدهد که مدلهای Diffusion میتوانند به کیفیت نمونه تصویری برتر از مدلهای Generative کنونی دست یابند.
آموزش پایدار
آموزش مدلهای Diffusion نسبت به آموزش مدهای GAN معمولاً پایدارتر است. GANها به متعادل کردن نرخ یادگیری شبکههای Generator و Discriminator نیاز دارند و زمانی که مولد نتواند تمام جنبههای توزیع داده را به تصویر بکشد، فرایند آموزش با مشکل مواجه خواهد شد. در مقابل، مدلهای Diffusion از آموزش مبتنی بر احتمال استفاده میکنند، که تمایل به پایداری بیشتر دارد.
تولید دادهها با حفظ حریم خصوصی
مدلهای Diffusion برای برنامههایی که حفظ حریم خصوصی دادهها در آنها اهمیت دارد، مناسب هستند. از آنجایی که مدل مبتنی بر تبدیلهای معکوس است، میتوان نمونههای داده مصنوعی را بدون افشای اطلاعات خصوصی اصلی دادههای اصلی تولید کرد.
مدیریت دادههای از دست رفته
مدلهای انتشار میتوانند دادههای از دست رفته را در طول فرآیند تولید مدیریت کنند. از آنجایی که انتشار معکوس میتواند با نمونههای داده ناقص کار کند، مدل میتواند نمونههای منسجمی را حتی زمانی که بخشهایی از دادههای ورودی گم شده باشد تولید کند.
مقاوم بودن در برابر Overfit شدن
مدلهای Generative سنتی مانند GANها میتوانند مستعد بیش overfit شدن باشند، که در آن مدل دادههای آموزشی را به خاطر میسپارد و نمیتواند به خوبی به دادههای دیده نشده تعمیم یابد. مدلهای انتشار به دلیل استفاده از آموزش مبتنی بر احتمال و ویژگیهای ذاتی انتشار معکوس، که تولید نمونه منسجمتر و متنوعتر را تشویق میکند، نسبت به Overfit شدن قویتر هستند.
فضای پنهان قابل تفسیر
در مقایسه با GAN ها، مدلهای انتشار اغلب Latent Space قابل تفسیرتری دارند. با معرفی یک متغیر پنهان در فرآیند انتشار معکوس، مدل میتواند تغییرات اضافی را ثبت کرده و نمونههای متنوعی تولید کند. فرآیند انتشار معکوس، توزیع داده پیچیده را به یک توزیع ساده نگاشت میکند و به فضای پنهان اجازه میدهد تا ویژگیها، الگوها و متغیرهای پنهان موجود در دادهها را نشان دهد. این تفسیرپذیری، همراه با انعطاف پذیری Latent Variable، میتواند برای درک بازنماییهای آموخته شده، به دست آوردن بینش در مورد داده ها، و امکان کنترل دقیق بر تولید تصویر ارزشمند باشد.
مقیاس پذیری به دادههای با ابعاد بالا
مدلهای Diffusion مقیاسپذیری امیدوارکنندهای را برای دادههای با ابعاد بالا، مانند تصاویر با وضوح بالا، نشان دادهاند. فرآیند انتشار گام به گام به مدل اجازه میدهد تا به طور موثر توزیعهای پیچیده داده را بدون غرق شدن در ابعاد بالای دادهها تولید کند.